


























Современные алгоритмы распознавания лиц еще в 2014 году добились точности в 99,8% и с тех пор почти достигли совершенства. Системы распознавания лиц сегодня применяются множеством крупных компаний и государств с различными целями – сегодня мы поговорим про принцип работы алгоритма, а также про оценку качества алгоритмов распознавания лиц подробнее.
Составные компоненты
Для успешной работы системы распознавания лиц требуется целый набор оборудования, а также специальных алгоритмов:
- Оптическая камера или лидар для получения фото или объемной карты лица.
- База данных с заранее проанализированными лицами.
- Алгоритмы нахождения лица на фотографии.
- Алгоритмы приведения найденного лица к определенному набору векторов.
- Алгоритмы сравнения полученных векторов с эталонными значениями.
Захват изображения
В первую очередь для работы системы распознавания лиц требуется исходное изображение – видеопоток с камеры нарезается на несколько кадров, которые затем отправляются в алгоритм. Система может использовать как плоское изображение, так и лидар, когда при помощи лазера создается объемная картинка. Очень часто лидар совмещается с изображением основной камеры, чтобы определить наличие в кадре реального человека, а не его фотографии.
Обнаружение лица

Для обнаружения лица могут использоваться специально настроенные нейросети, однако это достаточно долго и дорого. Именно поэтому сегодня чаще применяют простой метод Виолы – Джонса, в ходе которого изображение сканируется при помощи примитивов Хаара (черно-белых прямоугольников). При помощи такого сканирования находятся более светлые и более темные области изображения характерные конкретно для человеческого лица – например, обычно область глаз темнее лба, а переносица светлее бровей и так далее.
Так как подобные значения могут быть не только у человеческого лица, алгоритм работает в несколько этапов – сначала находится первый признак, который может свидетельствовать о наличии лица в кадре. Далее на том же месте система начинает искать второй и третий признаки, при совпадении которых можно уверенно заявить, что в кадре найдено лицо человека.
Так как подобные значения могут быть не только у человеческого лица, алгоритм работает в несколько этапов – сначала находится первый признак, который может свидетельствовать о наличии лица в кадре. Далее на том же месте система начинает искать второй и третий признаки, при совпадении которых можно уверенно заявить, что в кадре найдено лицо человека.
Антропометрия
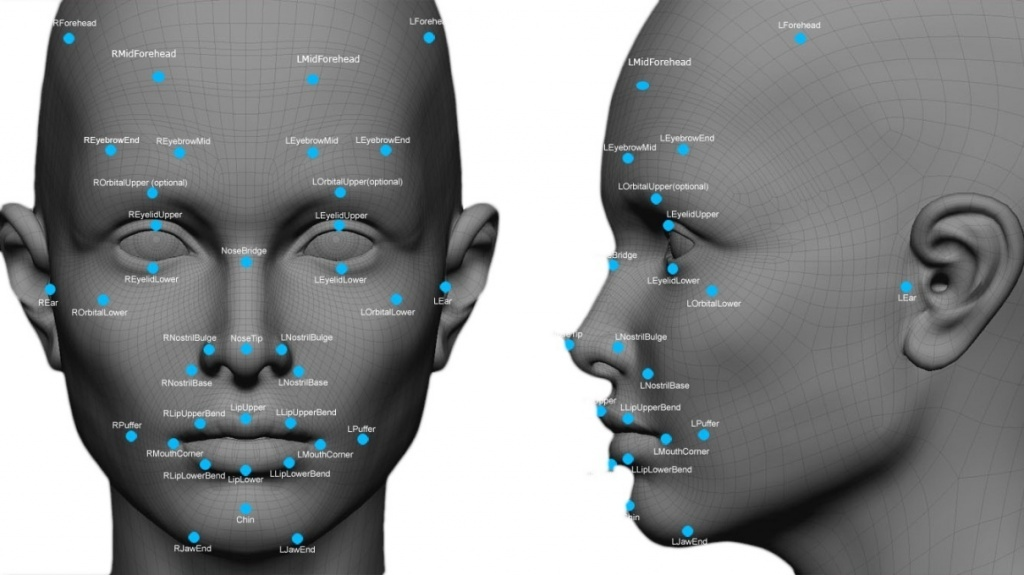
После получения области для анализа на определенном изображении, система распознавания лица подключает биометрический алгоритм – он выставляет антропометрические точки на лице в кадре. По данным точкам вычисляются индивидуальные характеристики человека, например, форма носа или челюсти, разрез глаз и так далее.
Исправление искажений
В идеале для анализа требуется лицо, которое смотрит прямо в камеру, однако на практике такое совпадение возникает крайне редко. Именно поэтому система самостоятельно проводит преобразование изображений, устраняя поворот и наклон головы в кадре. Кроме того, проводится 3D-реконструкция лица человека из двухмерного изображения – в результате можно получить четкий фронтальный снимок, который значительно повысит качество дальнейшего распознавания.
Построение вектора лица
На этом этапе к работе системы распознавания присоединяется нейросеть, которая присваивает каждому лицу вектор признаков – это определенное число, составленное из суммы характеристик человеческого лица. Данные характеристики описывают лицо вне зависимости от посторонних факторов, будь то макияж, прическа или возрастные изменения кожи.
Идентификация
Полученный в результате анализа вектор признаков сравнивается с базой данных других векторов – тогда система может успешно идентифицировать человека. Система распознавания лица также может работать в режиме обучения, тогда она записывает полученный вектор в базу данных под определенным идентификатором, чтобы использовать результат в дальнейшей работе.
Коэффициенты совпадения для каждого алгоритма свои – где-то допустимо совпадение лишь от 98%, что значительно повышает надежность системы, но затрудняет узнавания пользователя в определенных окружающих условиях. Либо совпадение может быть ниже – тогда система менее безопасна, однако более продуктивна. В любом случае, данные нюансы напрямую зависят от настройки алгоритма и требований его эксплуатации.
Коэффициенты совпадения для каждого алгоритма свои – где-то допустимо совпадение лишь от 98%, что значительно повышает надежность системы, но затрудняет узнавания пользователя в определенных окружающих условиях. Либо совпадение может быть ниже – тогда система менее безопасна, однако более продуктивна. В любом случае, данные нюансы напрямую зависят от настройки алгоритма и требований его эксплуатации.
Оценка качества алгоритмов распознавания лиц
Для внедрения системы распознавания лиц в определенные коммерческие или государственные отрасли важно уметь измерять точность работы системы – это позволит выбирать подходящие к конкретной бизнес-задаче инструменты без риска столкнуться с финансовыми потерями или упустить прибыль.
Зачем применяются системы распознавания лиц?
Современные алгоритмы для распознавания лиц могут быть настроены для решения различных задач пользователя – они могут находить лицо на фотографии или видеозаписи, могут определять пол и возраст человека в кадре, искать нужного человека среди множеств изображений других лиц, а также проверять, что на двух фотографиях изображен один и тот же человек. Две последние задачи называются идентификацией и верификацией – для их решения необходимы векторы признаков, которые получают в процессе распознавания лица.
Таким образом, при идентификации человека проводится поиск ближайших векторов признаков, а при верификации анализируется порог расстояний между векторами. Комбинация двух данных действий дает возможность идентифицировать человека среди множества фотографий лиц – это open-set identification или идентификация на открытом множестве.
Количественно оценить схожесть лиц можно при помощи расстояния в пространстве между векторами признаков лиц – конкретная функция расстояния обычно идет в составе продукта по распознаванию лиц. Так как идентификация и верификация человека – это разные задачи, то и метрики для оценки качества работы систем распознавания будут разными. Обратите внимание, что для оценки точности алгоритма нужен также размеченный набор изображений – датасет.
Таким образом, при идентификации человека проводится поиск ближайших векторов признаков, а при верификации анализируется порог расстояний между векторами. Комбинация двух данных действий дает возможность идентифицировать человека среди множества фотографий лиц – это open-set identification или идентификация на открытом множестве.
Количественно оценить схожесть лиц можно при помощи расстояния в пространстве между векторами признаков лиц – конкретная функция расстояния обычно идет в составе продукта по распознаванию лиц. Так как идентификация и верификация человека – это разные задачи, то и метрики для оценки качества работы систем распознавания будут разными. Обратите внимание, что для оценки точности алгоритма нужен также размеченный набор изображений – датасет.
Что такое датасет в системе распознавания лиц?
Практически любая система распознавания лиц строится на машинном обучении – алгоритмы обучаются при помощи объемных датасетов с уже размеченными изображениями. От качества имеющегося набора данных будет зависеть успешность алгоритма при решении определённой задачи. Именно поэтому очень важно правильно выбрать необходимый датасет – в идеале он должен быть максимально похож на те изображения, с которыми система распознавания будет работать ежедневно. Таким образом, большинство компаний тратят время и средства для сбора и разметки своего определенного набора данных.
Конечно, гораздо проще воспользоваться уже готовыми публичными датасетами, например, LFW или MegaFace. Датасеты от LFW содержат 6000 пар изображений лиц, однако не подходят для множества сценариев из реальной жизни – такой набор данных не позволяет измерить низкие уровни ошибок распознавания. Датасеты от MegaFace имеют больше пар изображений, потому подойдут для систем распознавания лиц на больших масштабах, однако эти изображения есть в открытом доступе, потому должны применяться с осторожностью.
Конечно, гораздо проще воспользоваться уже готовыми публичными датасетами, например, LFW или MegaFace. Датасеты от LFW содержат 6000 пар изображений лиц, однако не подходят для множества сценариев из реальной жизни – такой набор данных не позволяет измерить низкие уровни ошибок распознавания. Датасеты от MegaFace имеют больше пар изображений, потому подойдут для систем распознавания лиц на больших масштабах, однако эти изображения есть в открытом доступе, потому должны применяться с осторожностью.
Переобучение систем распознавания
Одним из феноменов машинного обучения является переобучение – алгоритм распознавания показывает хороший результат на лицах, которые использовались при его обучении, однако результаты распознавания новых данных значительно отстают по качеству. Допустим, клиент устанавливает пропускную систему распознавания лиц, собирает набор фотографий людей, которым разрешен доступ и обучает алгоритм отличать лица этих людей от других человеческих лиц. Система работает хорошо, но через некоторое время требуется расширить список людей с допуском – тогда алгоритм распознавания начинает отказывать в доступе новым людям. Все дело в том, что тестирование системы проходило на тех же лицах, на которых проходило ее обучение – никто не проводил измерения точности на новых фотографиях.
Неправильное тестирование алгоритма является очень распространенной ошибкой, поэтому система всегда должна тестироваться на новых данных, которые алгоритм будет обрабатывать в реальном времени. Нельзя использовать фотографии лиц, на которых обучался алгоритм распознавания, для его дальнейшего тестирования – для этого нужно брать закрытый датасет. Если вы хотите воспользоваться публичным датасетом, убедитесь, что поставщик систем распознавания не использовал его в процессе обучения или настройки своего алгоритма.
Неправильное тестирование алгоритма является очень распространенной ошибкой, поэтому система всегда должна тестироваться на новых данных, которые алгоритм будет обрабатывать в реальном времени. Нельзя использовать фотографии лиц, на которых обучался алгоритм распознавания, для его дальнейшего тестирования – для этого нужно брать закрытый датасет. Если вы хотите воспользоваться публичным датасетом, убедитесь, что поставщик систем распознавания не использовал его в процессе обучения или настройки своего алгоритма.
Что такое метрики?
Как только выбран датасет, необходимо выбрать и метрику для оценки результатов – это функция, которая принимает результаты работы алгоритма идентификации или верификации лица и выдает число, соответствующее качеству работы системы на определенном датасете. Одно число для сравнения разных алгоритмов позволяет сжато представить результаты распознавания, чтобы облегчить процесс принятия решений.
Метрики для верификации
Верификация лица сводится к принятию бинарного решения – «да/нет», то есть два изображения принадлежат одному лицу или два изображения содержат разные лица. В данных задачах есть 2 возможных ответа от алгоритма и 2 варианта истинного положения вещей, итого возможно 4 исхода. Два исхода соответствуют правильным ответам алгоритма, а два – ошибкам первого и второго рода.
К ошибкам первого рода относят ошибки «false accept», «false positive» или «false match» - неверно принято. К ошибкам второго рода относятся «false reject», «false negative» или «false non-match» - неверно отвергнуто. Получив сумму ошибок разного рода по парам изображений в датасете и разделив результат на количество пар, можно вычислить показатели FAR и FRR – частота неверных принятий и частота неверных отказов соответственно. Например, если мы говори про систему контроля доступа, вариант неверного принятия даст доступ человеку, для которого доступ не предусмотрен, в то время как ошибка «неверно отвергнуто» не предоставит доступ авторизованному лицу.
С точки зрения бизнеса подобные ошибки имеют различную стоимость, поэтому должны анализироваться отдельно – именно поэтому производители систем распознавания лиц обычно дают возможность пользователю настроить алгоритм таким образом, чтобы минимизировать определенный вид ошибок. В таком случае система возвращает не бинарное значение, а число, которое отражает уверенность алгоритма распознавания в принятом решении – тогда пользователь сам выбирает порог принятия решения, фиксируя уровень ошибок на заданном значении.
К ошибкам первого рода относят ошибки «false accept», «false positive» или «false match» - неверно принято. К ошибкам второго рода относятся «false reject», «false negative» или «false non-match» - неверно отвергнуто. Получив сумму ошибок разного рода по парам изображений в датасете и разделив результат на количество пар, можно вычислить показатели FAR и FRR – частота неверных принятий и частота неверных отказов соответственно. Например, если мы говори про систему контроля доступа, вариант неверного принятия даст доступ человеку, для которого доступ не предусмотрен, в то время как ошибка «неверно отвергнуто» не предоставит доступ авторизованному лицу.
С точки зрения бизнеса подобные ошибки имеют различную стоимость, поэтому должны анализироваться отдельно – именно поэтому производители систем распознавания лиц обычно дают возможность пользователю настроить алгоритм таким образом, чтобы минимизировать определенный вид ошибок. В таком случае система возвращает не бинарное значение, а число, которое отражает уверенность алгоритма распознавания в принятом решении – тогда пользователь сам выбирает порог принятия решения, фиксируя уровень ошибок на заданном значении.
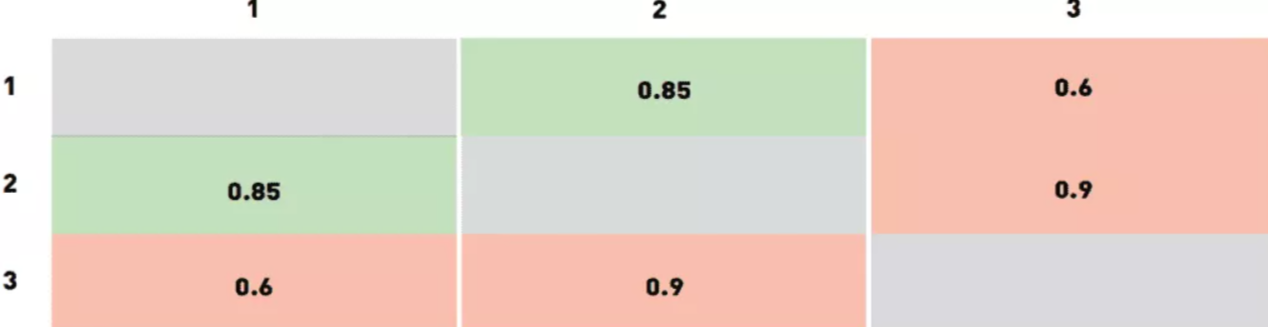
В качестве примера воспользуемся таблицей выше – мы берем датасет из трех изображений, фото под номером 1 и 2 принадлежат одному человеку, а фотография под номером 3 кому-то другому. Программа оценивает свою уверенность для каждой пары фотографий так, как указано в таблице. Любой порог ниже показателя 0,6 будет приводить к «неверному принятию» для лиц 2-3 и 1-3.
Если выбрать порог в диапазоне от 0,6 до 0,85, пара лиц 1-3 будет отвергаться системой, пара лиц 1-2 будет приниматься как нужно, а вот пара 2-3 начнет ложно приниматься алгоритмом. Если поднять порог до значений от 0,85 до 0,9 – пара лиц 1-2 станет ложно отвергаться системой. При значении порога выше 0,9 пары лиц 1-3 и 2-3 будут безошибочно отвергаться, однако сохранится ошибка ложного отказа для пары лиц 1-2.
Исходя из вышеописанного, лучшими решениями являются порог от 0,6 до 0,85 и порог выше 0,9. Какое значение выбрать в качестве финального решает пользователь на основании стоимость ошибок разного типа. Обратите внимание, что для реальных датасетов порог принятия решения получится более точным. Обычно производители систем распознавания выставляют значения порога по умолчанию для разных показателей FAR, которые вычисляются из датасетов разработчика.
По мере снижения FAR требуется больше положительных пар изображений, чтобы точно выстроить значение порога. Собрать такой набор данных достаточно сложно, поэтому при необходимости получения низких значений FAR рекомендуется использовать бенчмарки NIST Face Recognition Vendor или MegaFace.
Если выбрать порог в диапазоне от 0,6 до 0,85, пара лиц 1-3 будет отвергаться системой, пара лиц 1-2 будет приниматься как нужно, а вот пара 2-3 начнет ложно приниматься алгоритмом. Если поднять порог до значений от 0,85 до 0,9 – пара лиц 1-2 станет ложно отвергаться системой. При значении порога выше 0,9 пары лиц 1-3 и 2-3 будут безошибочно отвергаться, однако сохранится ошибка ложного отказа для пары лиц 1-2.
Исходя из вышеописанного, лучшими решениями являются порог от 0,6 до 0,85 и порог выше 0,9. Какое значение выбрать в качестве финального решает пользователь на основании стоимость ошибок разного типа. Обратите внимание, что для реальных датасетов порог принятия решения получится более точным. Обычно производители систем распознавания выставляют значения порога по умолчанию для разных показателей FAR, которые вычисляются из датасетов разработчика.
По мере снижения FAR требуется больше положительных пар изображений, чтобы точно выстроить значение порога. Собрать такой набор данных достаточно сложно, поэтому при необходимости получения низких значений FAR рекомендуется использовать бенчмарки NIST Face Recognition Vendor или MegaFace.
ROC-кривые
Любые ошибки отличаются по своей стоимости, потому клиент может самостоятельно смещать баланс в сторону определенных ошибок – для этого рассматривают широкий диапазон значений порога. Для удобства визуализации точности алгоритма в зависимости от значений FAR строят специальные ROC-кривые, которые затем анализируются.
Уверенность алгоритма и порог принимаются из фиксированного интервала – эти величины ограничены снизу и сверху. Например, берется интервал от 0 до 1, далее измеряется количество ошибок при вариации значений порога в пределах от 0 до 1 с небольшим шагом. В результате для каждого значения порога получается свой показатель FAR и TAR (частота правильных решений). Затем рисуются точки, чтобы FAR соответствовал оси абсцисс, а TAR оси ординат:
Уверенность алгоритма и порог принимаются из фиксированного интервала – эти величины ограничены снизу и сверху. Например, берется интервал от 0 до 1, далее измеряется количество ошибок при вариации значений порога в пределах от 0 до 1 с небольшим шагом. В результате для каждого значения порога получается свой показатель FAR и TAR (частота правильных решений). Затем рисуются точки, чтобы FAR соответствовал оси абсцисс, а TAR оси ординат:
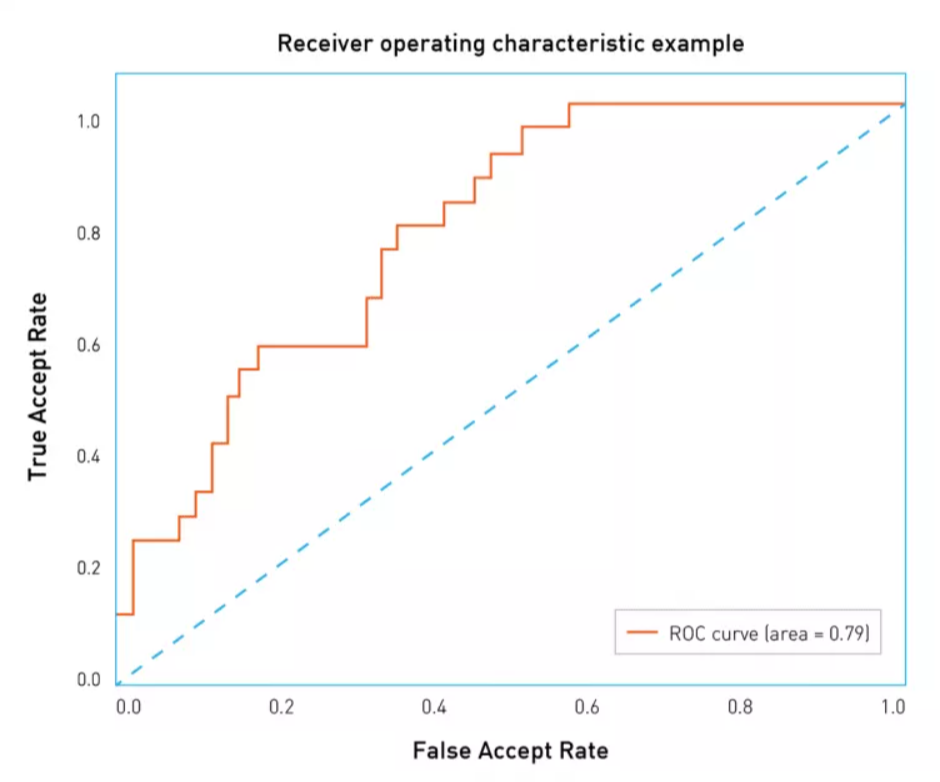
Первая точка будет иметь координаты 1,1, порог равный 0 означает, что система принимает все пары лиц и не отвергает ни одной. Последняя точка с координатами 0,0 означает, что при пороге 1 не принимается ни одна пара лиц и отвергаются все лица. В других точках графика ROC-кривая обычно выпуклая, а наихудшая кривая расположена на диагонали графика и соответствует случайному угадыванию исхода. Наилучшая возможная кривая строится в форме треугольника с вершинами 0,0; 0,1; 1,1 – такого результата сложно добиться на датасетах большого размера.
Метрики для идентификации
Помимо верификации, второй важной задачей современных систем распознавания лиц является идентификация – поиск нужного лица среди набора изображений. Результаты поиска в данном случае сортируются алгоритмом в зависимости от его уверенности. Идентификация может быть двух видов – closed-set, когда искомый человек есть в базе или open-set, когда человека может не быть в базе лиц.
Точность является самой понятной и надежной метрикой для оценки closed-set идентификации – она отражает количество раз, когда нужная персона была среди результатов поиска по лицу. Допустим, существует веб-сайт, на котором размещаются десять результатов поиска. Необходимо измерить количество раз, сколько искомый человек попадал в первые десять ответов алгоритма – полученное число называют Top-N точность, а показатель N в нашем случае будет равен 10.
Каждое испытание лиц подразумевает выбор изображения человека, которого нужно найти, а также галерею лиц, среди которой проводится поиск. Галерея обязательно должна содержать еще хотя бы одно дополнительное изображение искомого человека. Первые 10 результатов просматриваются и проверяются на совпадения, чтобы вычислить точность, необходимо сложить все испытания, в которых искомый человек был в результатах поиска, и разделить на общее количество испытаний.
Если говорить про open-set идентификацию – это поиск лица, наиболее похожего на лицо с изображения с целью дальнейшего определения, является ли кто-то на найденных изображениях искомым человеком на основании уверенности алгоритма распознавания. Такая идентификация может являть собой комбинацию closed-set подхода и верификации, потому для оценки ее качества применяются все метрики, что и для верификации.
Open-set идентификация может сводиться к попарным сравнениям искомого изображения со всеми изображениями в датасете, но на практике это редко используется из соображений скорости вычислений. Современные алгоритмы распознавания лиц часто комплектуются быстрыми алгоритмами поиска, которые помогают среди миллионов лиц найти похожее лицо за считанные секунды.
Точность является самой понятной и надежной метрикой для оценки closed-set идентификации – она отражает количество раз, когда нужная персона была среди результатов поиска по лицу. Допустим, существует веб-сайт, на котором размещаются десять результатов поиска. Необходимо измерить количество раз, сколько искомый человек попадал в первые десять ответов алгоритма – полученное число называют Top-N точность, а показатель N в нашем случае будет равен 10.
Каждое испытание лиц подразумевает выбор изображения человека, которого нужно найти, а также галерею лиц, среди которой проводится поиск. Галерея обязательно должна содержать еще хотя бы одно дополнительное изображение искомого человека. Первые 10 результатов просматриваются и проверяются на совпадения, чтобы вычислить точность, необходимо сложить все испытания, в которых искомый человек был в результатах поиска, и разделить на общее количество испытаний.
Если говорить про open-set идентификацию – это поиск лица, наиболее похожего на лицо с изображения с целью дальнейшего определения, является ли кто-то на найденных изображениях искомым человеком на основании уверенности алгоритма распознавания. Такая идентификация может являть собой комбинацию closed-set подхода и верификации, потому для оценки ее качества применяются все метрики, что и для верификации.
Open-set идентификация может сводиться к попарным сравнениям искомого изображения со всеми изображениями в датасете, но на практике это редко используется из соображений скорости вычислений. Современные алгоритмы распознавания лиц часто комплектуются быстрыми алгоритмами поиска, которые помогают среди миллионов лиц найти похожее лицо за считанные секунды.
Частые ошибки
В процессе тестирования систем для распознавания лиц встречаются проблемы и ошибки, которых можно избежать:
- Тестирование на недостаточном датасете – при выборе набора данных для тестирования алгоритмов распознавания лиц необходимо правильно учитывать размер датасета. Это одно из его важнейших свойств, выбирать размер датасета нужно в соответствии с требованиями бизнеса по значениям FAR и TAR.
- Тестирование при единственном значении порога – иногда тестирование систем распознавания лиц ведется при фиксированном пороговом значение, потому во внимание принимают лишь один тип ошибок.
- Сравнение результатов на разных датасетах – наборы данных отличаются своими размерами, сложностью и качеством, потому и результат работы систем распознавания будет варьироваться в зависимости от датасета.
- Не делайте выводы на основе тестирования на единственном наборе данных – проводите тестирование на нескольких датасетах, так как при выборе единственного публичного нет гарантий, что он не использовался для обучения или настройки алгоритма.